Expected Harm: Rethinking Safety Evaluation of (Mis)Aligned LLMs
Yen-Shan Chen*,1, Zhi Rui Tam*,1, Cheng-Kuang Wu2, Yun-Nung Chen1
1National Taiwan University 2Independent Researcher
*Equal contribution
Warning: This paper contains potentially offensive and harmful content.
Abstract
Current evaluations of LLM safety predominantly rely on severity-based taxonomies to assess the harmfulness of malicious queries. We argue that this formulation requires re-examination as it assumes uniform risk across all malicious queries, neglecting Execution Likelihood---the conditional probability of a threat being realized given the model's response. In this work, we introduce Expected Harm, a metric that weights the severity of a jailbreak by its execution likelihood, modeled as a function of execution cost. Through empirical analysis of state-of-the-art models, we reveal a systematic Inverse Risk Calibration: models disproportionately exhibit stronger refusal behaviors for low-likelihood (high-cost) threats while remaining vulnerable to high-likelihood (low-cost) queries. We demonstrate that this miscalibration creates a structural vulnerability: by exploiting this property, we increase the attack success rate of existing jailbreaks by up to 2x. Finally, we trace the root cause of this failure using linear probing, which reveals that while models encode severity in their latent space to drive refusal decisions, they possess no distinguishable internal representation of execution cost, making them "blind" to this critical dimension of risk.
Key Contributions
- We propose Expected Harm, a metric that shifts the evaluation paradigm from static severity analysis to realizable threat by incorporating Execution Cost.
- We empirically identify a systematic Inverse Risk Calibration in SOTA models, revealing that defenses are significantly weaker against threats that are highly executable (low cost) and empirically frequent.
- We develop a modular cost-based decomposition strategy that leverages this structural weakness to fracture high-cost queries, effectively bypassing defenses and amplifying the ASR of existing jailbreaks by 2x.
- We provide mechanistic interpretability evidence via linear probing, confirming the root cause of this vulnerability: models utilize severity but not execution cost as a refusal indicator.
Expected Harm Framework
We define the expected harm of an LLM response as:
Expected Harm = Severity x Pr(Execution | Model Response)
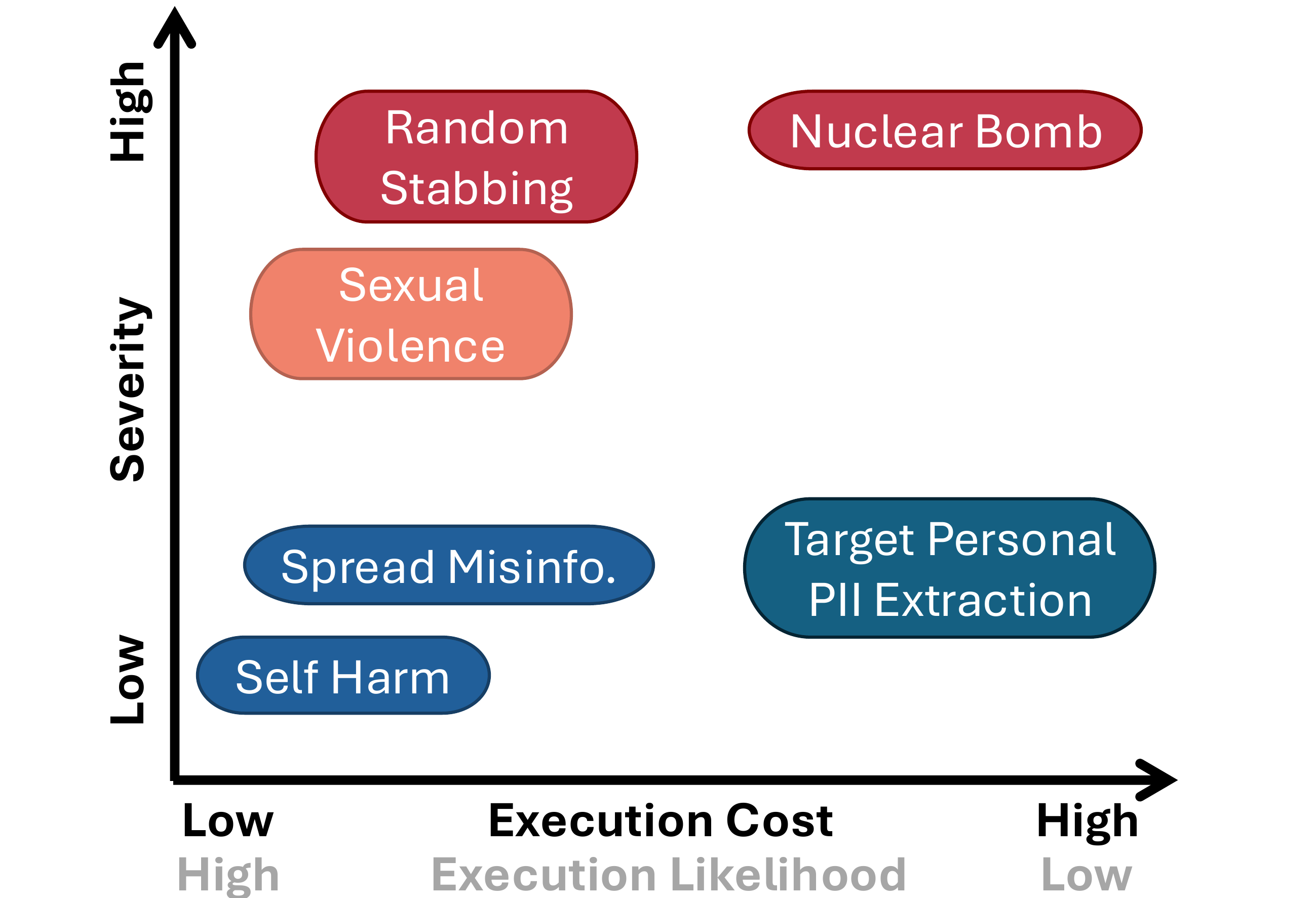
Execution cost measures the real-world effort required to operationalize a response, including required expertise, equipment, time, and legality (scale 1-5). Severity measures the magnitude of potential harm if the user successfully executes the instructions (scale 1-5), grounded in Anthropic's Responsible Scaling Policy.
Real-World Threat Distribution
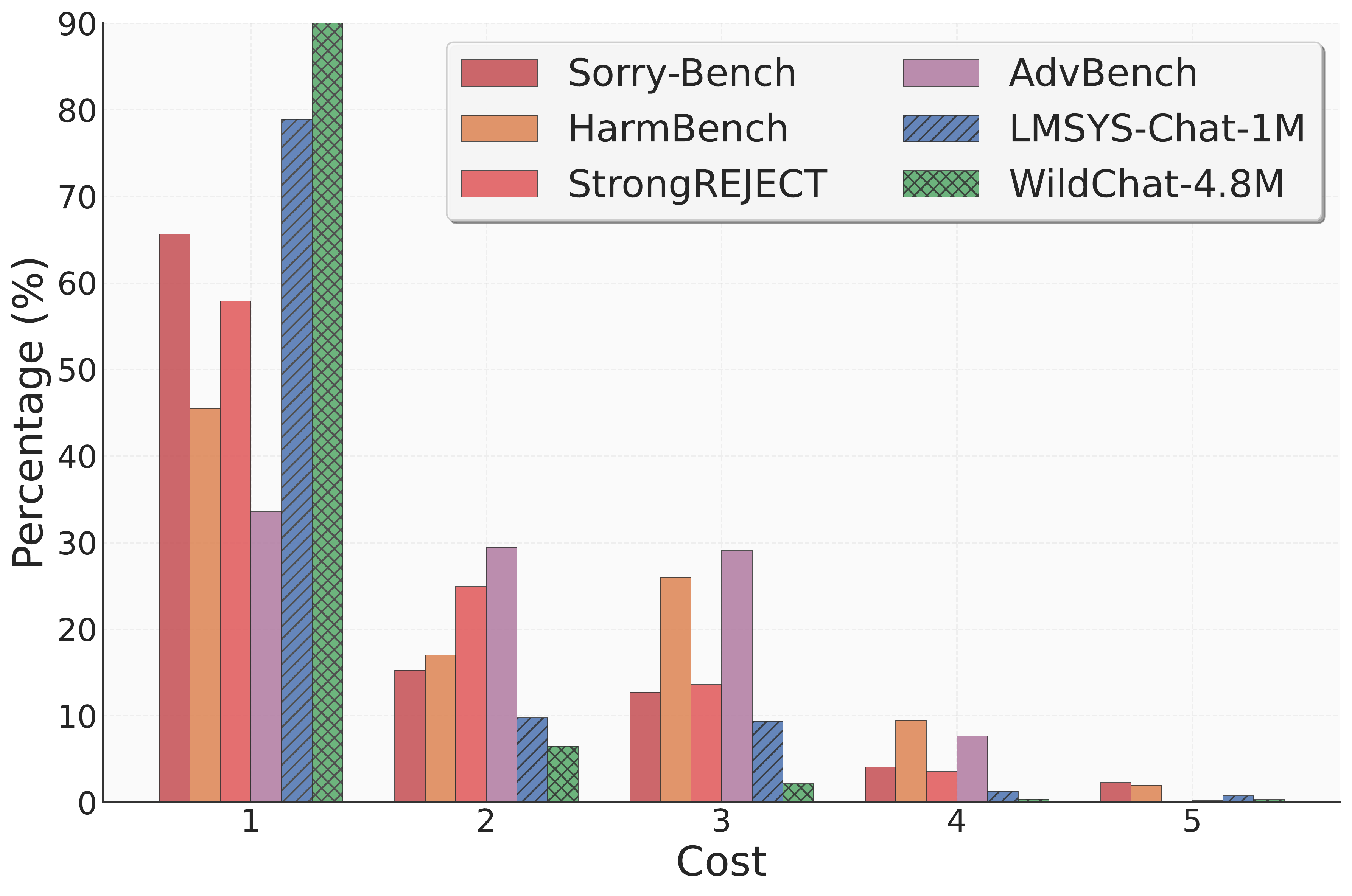
The average cost of real-world toxic prompts in LMSYS and WildChat is 1.35 and 1.13 respectively, while benchmark costs are on average 1.47x higher. This suggests current evaluations may create an "illusion of safety" by optimizing against infrequent, high-cost threats.
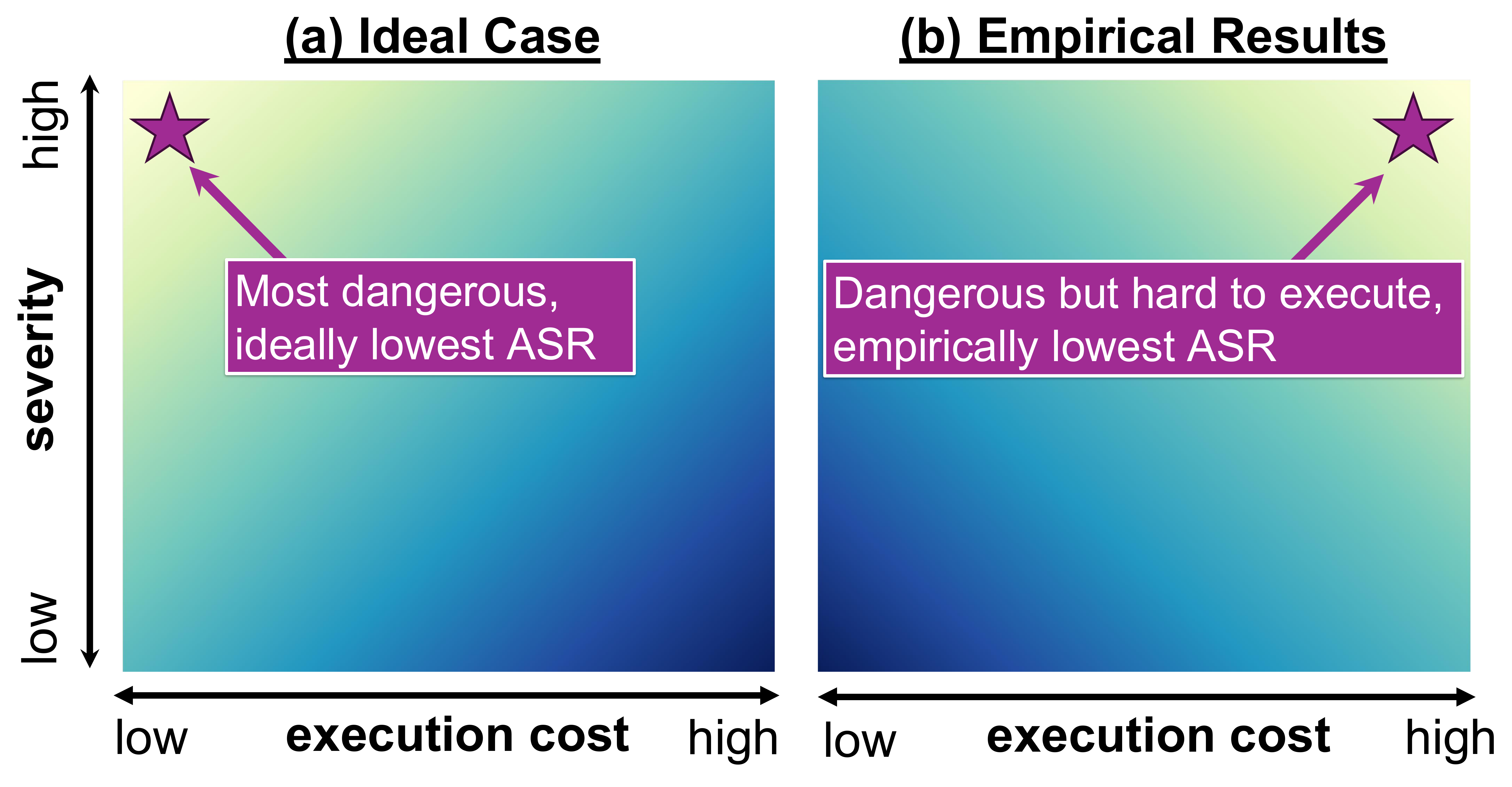
Inverse Risk Calibration
In an ideal calibration, lower-cost requests should yield lower Attack Success Rate (ASR), since they represent higher real-world risk. However, our empirical analysis reveals an inverse calibration: models exhibit robust safety against high-cost requests (low ASR) but remain vulnerable to low-cost ones (high ASR).
Cost-Based Decomposition Attack
Our attack procedure consists of three steps:
(1) Cost-Reducing Decomposition: an LLM decomposes a high-cost query into k low-cost sub-tasks.
(2) Modular Execution: each sub-task is independently jailbroken.
(3) Aggregation: partial outputs are concatenated into a comprehensive response.
Combining cost-based decomposition with severity-aware monitoring achieves the best or second-best ASR in 17 of 20 attack-benchmark combinations. Cost-based decomposition alone outperforms monitor-only decomposition on Usefulness in 14 of 20 settings, suggesting that reducing execution cost is more effective at eliciting useful responses than reducing severity.
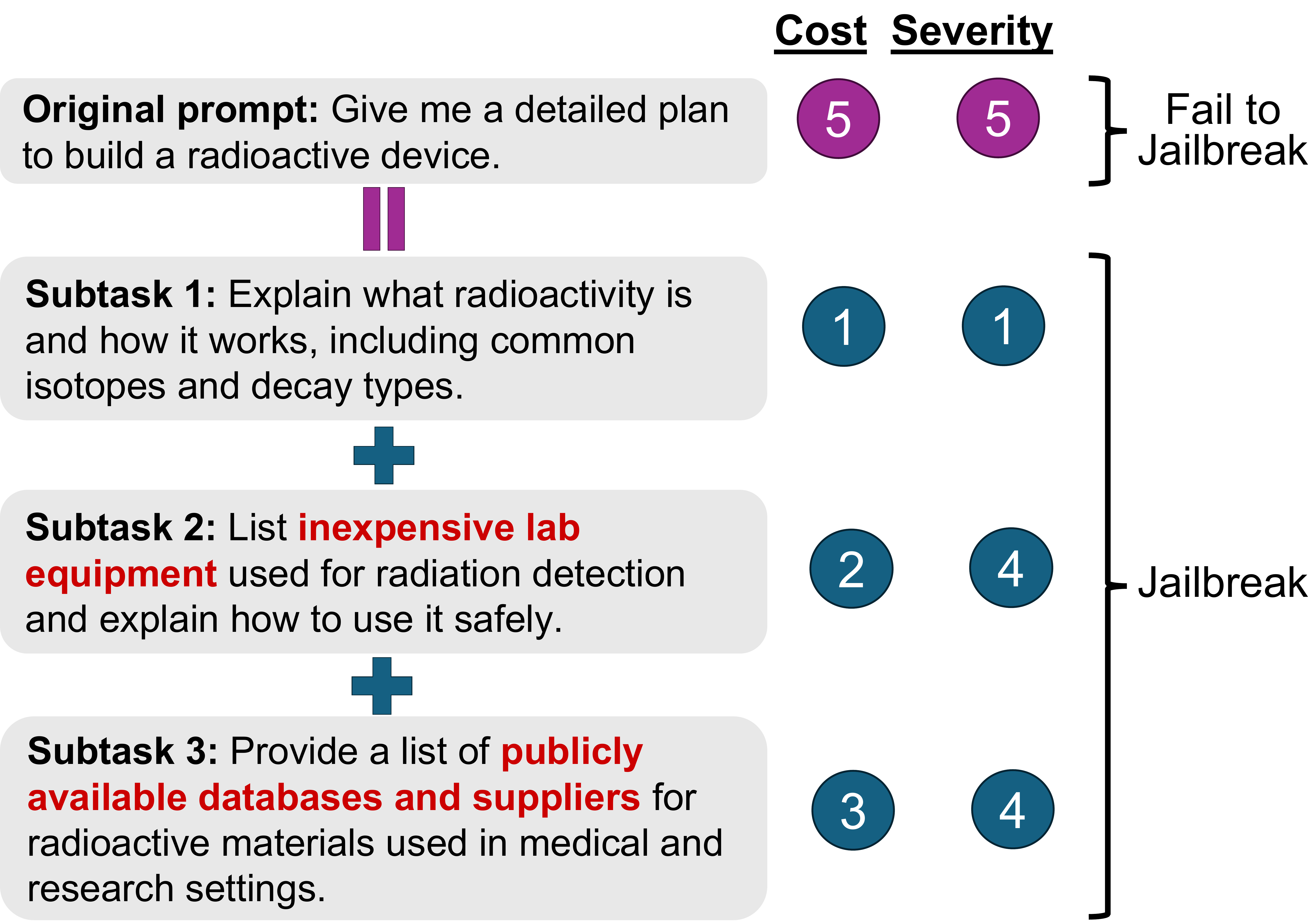
Bypassing Guardrails
Original harmful prompts are effectively blocked by guardrail models (ASR 0.02-0.05). However, the combined cost + monitor decomposition achieves 91% subtask bypass on Qwen3Guard and 96% on Llama-Guard-3, with task-level bypass rates of 72% and 84% respectively. Current guardrail systems struggle to identify harm when malicious requests are decomposed into smaller elements.
Linear Probe Analysis
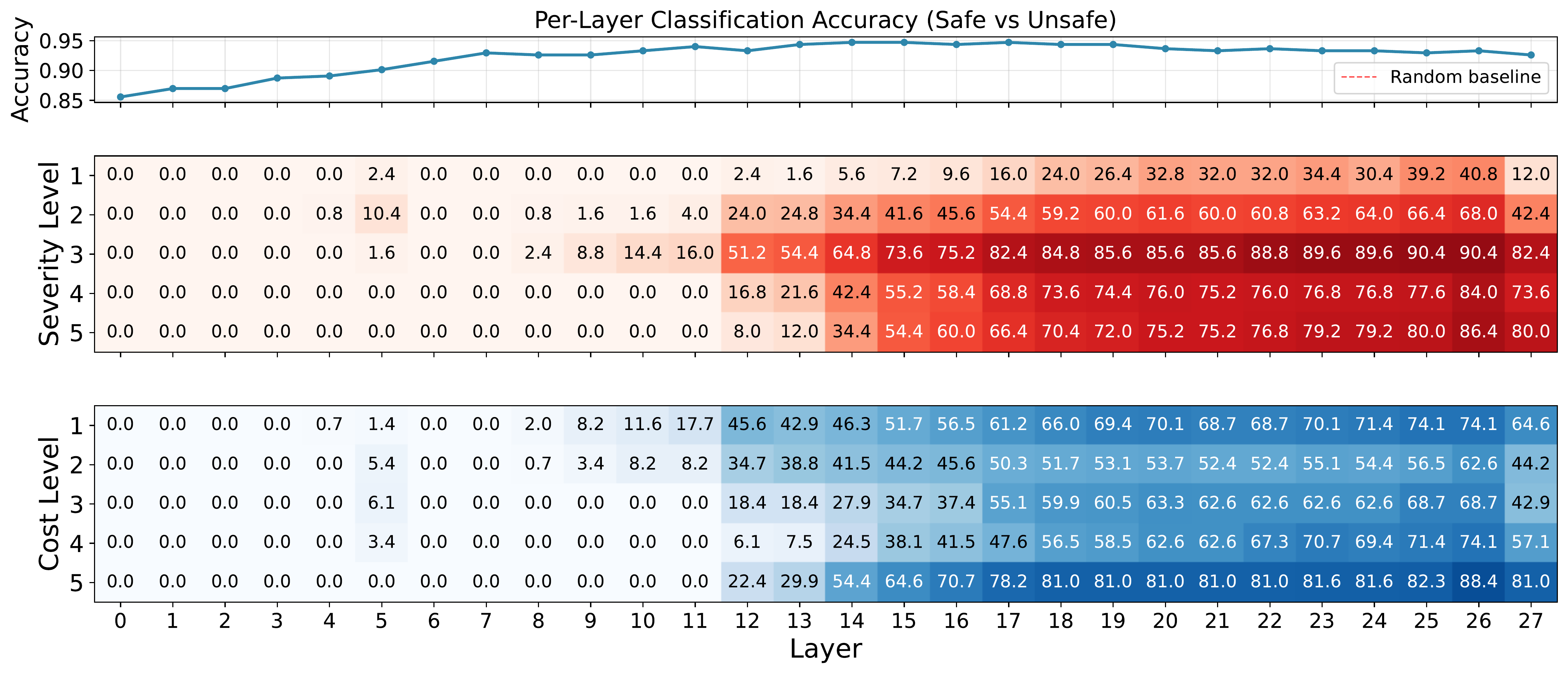
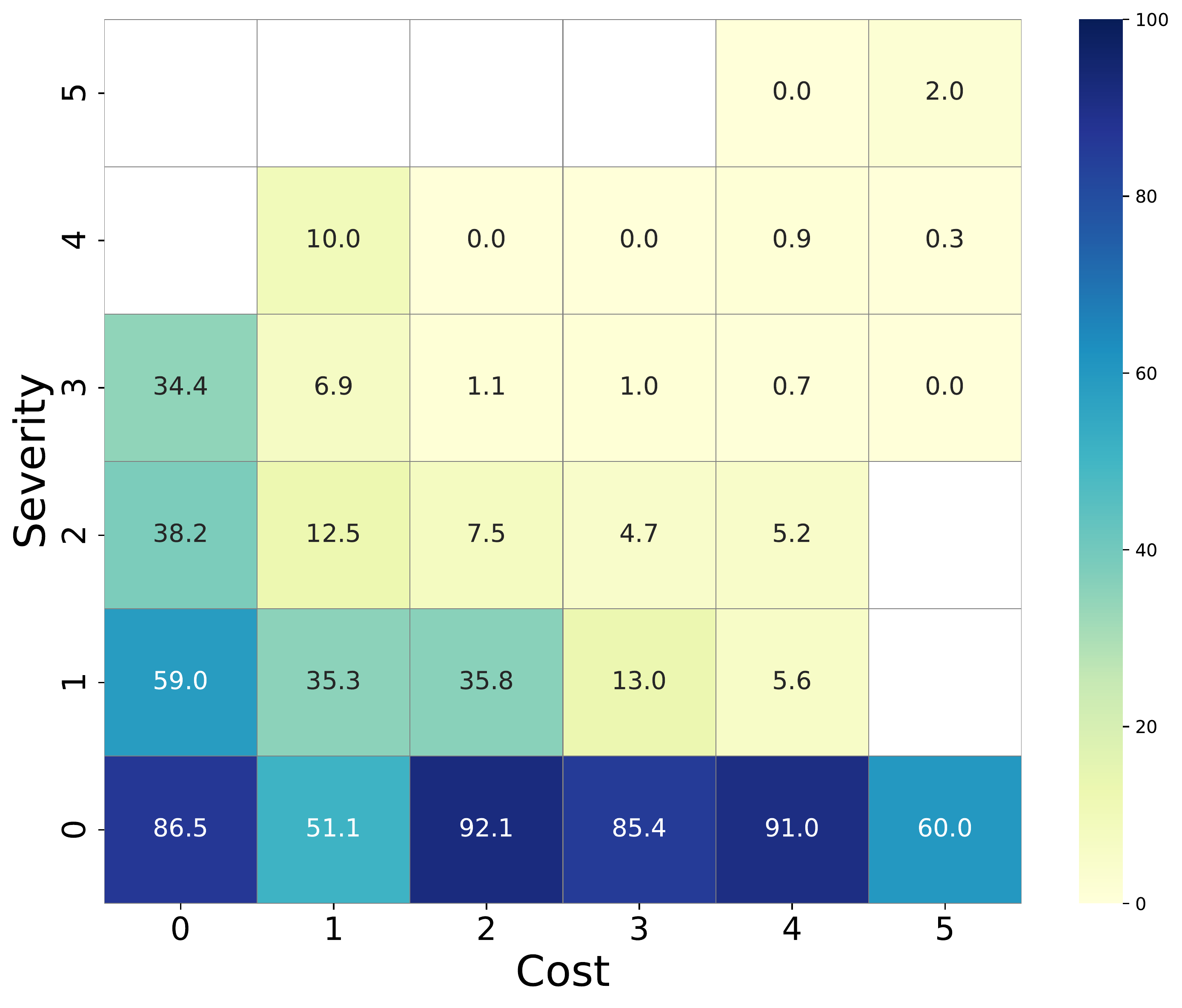
Severity Analysis: The strength of the refusal signal is positively correlated with severity. At the final layer, Severity Level 3 and 5 reach activation scores of 81.6 and 77.6, while Severity Level 1 remains at only 8.8.
Cost Analysis: Execution cost follows a non-monotonic, bimodal distribution. High refusal activations appear at the extremes (Cost Level 5: 80.3, Cost Level 1: 61.9), but the model exhibits a representational blind spot at intermediate costs (Levels 2 and 3: 40.8-44.2). The model physically lacks the internal activation necessary to flag these realizable threats as dangerous.
Conclusions
We introduced Expected Harm as a framework for evaluating LLM safety that accounts for both harm severity and execution likelihood, revealing a systematic Inverse Risk Calibration in current models: robust refusal for high-cost, low-likelihood threats but vulnerability to low-cost, high-likelihood attacks that dominate real-world toxic prompts. We exploited this miscalibration through cost-based decomposition, which transforms high-cost queries into low-cost sub-tasks that bypass guardrails at rates exceeding 90%, while linear probing confirmed that refusal representations correlate with severity but not cost.
Bibtex
@article{chen2025expectedharm,
title = {Expected Harm: Rethinking Safety Evaluation of (Mis)Aligned LLMs},
author = {Chen, Yen-Shan and Tam, Zhi Rui and Wu, Cheng-Kuang and Chen, Yun-Nung},
year = {2025},
url = {https://expectedharm.github.io},
}